Regularization (การปรับแต่ง) เป็นเทคนิคที่ใช้ในการลด(overfitting) ในโมเดลประสาทเทียม (Neural Network) และอื่นๆ ในกรณีที่โมเดลมีขนาดใหญ่หรือมีจำนวนพารามิเตอร์สูง โดยการปรับแต่งช่วยลดโอกาสในการเกิดความเกลียดเกรง และทำให้โมเดลทำนายข้อมูลที่ไม่เคยเห็นมาก่อนได้ดีขึ้น
L1 Regularization หมายถึงการเพิ่มค่าของผลรวมค่าสัมบูรณ์ของพารามิเตอร์ในฟังก์ชันความสูญเสีย (loss function) ซึ่งทำให้โมเดลมีความเอาใจใส่ต่อความสำคัญของพารามิเตอร์แต่ละตัว ส่วนพารามิเตอร์ที่มีค่าเล็กๆ จะถูกลดลงในกระบวนการเรียนรู้
L2 Regularization หมายถึงการเพิ่มค่าของผลรวมของค่าเล็กๆ ของพารามิเตอร์ในฟังก์ชันความสูญเสีย การเพิ่มค่าเล็กๆ นี้จะทำให้พารามิเตอร์มีค่าที่เกินมากน้อยและทำให้โมเดลมีความเสถียรและไม่เกิดความเกลียดเกรง
ความแตกต่างระหว่าง L1 และ L2 คือการเพิ่มค่าของค่าสัมบูรณ์ (magnitude) ของพารามิเตอร์ในฟังก์ชันความสูญเสีย ใน L1 ค่าของพารามิเตอร์จะถูกลดเป็นจำนวนบวกและลบที่เท่ากัน ส่วนใน L2 ค่าของพารามิเตอร์จะถูกลดเป็นจำนวนบวกเท่านั้น ทำให้ L1 มีความเป็นประเภทการหดหรือการกระจายที่ดีกว่า L2
ภาพจาก https://medium.com/analytics-vidhya/l1-vs-l2-regularization-which-is-better-d01068e6658c
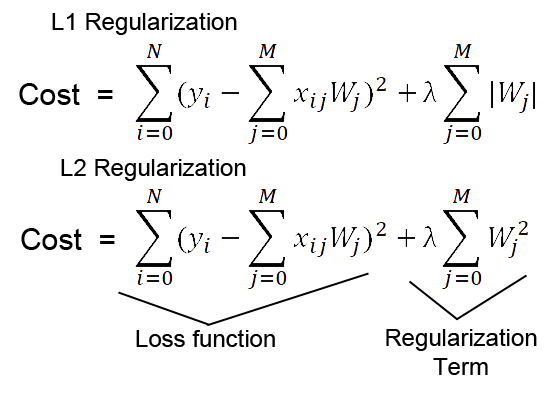
การเลือกใช้ L1 Regularization หรือ L2 Regularization ขึ้นอยู่กับลักษณะของปัญหาที่ต้องการแก้ไขและลักษณะของโมเดลประสาทเทียมที่ใช้ในการเรียนรู้ ดังนี้:
ใช้ L1 Regularization เมื่อ:
- ต้องการทำลดค่าสัมบูรณ์ของพารามิเตอร์ที่มีความเกี่ยวข้องกับโมเดล เพื่อให้โมเดลมีความกระชับและเลือกเฉพาะคุณลักษณะที่สำคัญเท่านั้น
- ต้องการลดขนาดของโมเดลเพื่อลดภาระการคำนวณ โดยการทำให้พารามิเตอร์ไม่สำคัญมีค่าเป็นศูนย์ ทำให้ส่งผลให้คำนวณที่ซับซ้อนลดลง
ใช้ L2 Regularization เมื่อ:
- ต้องการปรับแต่งโมเดลเพื่อลดoverfitting ป้องกันการเกิดการเรียนรู้ที่เกินขนาด (overfitting)
- ต้องการทำให้โมเดลมีความสามารถในการทำนายข้อมูลที่ไม่เคยเห็นมาก่อน (generalization) ดีขึ้น
- ต้องการให้โมเดลมีความเสถียรและไม่เกิดการเกิดการแย่งกันระหว่างพารามิเตอร์
อย่างไรก็ตาม การเลือกใช้ L1 หรือ L2 ไม่มีกฎเกณฑ์ที่แน่นอน และมักจะขึ้นอยู่กับการทดลองและการประเมินผลในกรณีนั้นๆ เพื่อหาวิธีการที่ใช้งานได้ดีที่สุดสำหรับปัญหาและโมเดลที่มีอยู่