Activation Function (ฟังก์ชันกระตุ้น) เป็นฟังก์ชันที่นำมาใช้ในโครงข่ายประสาทเทียม (Neural Networks) เพื่อให้โมเดลสามารถเรียนรู้และเชื่อมโยงข้อมูลนำเข้าได้ หลังจากที่ผลรวมของข้อมูลนำเข้าและค่าน้ำหนักถูกคำนวณแล้ว ฟังก์ชันกระตุ้นจะทำหน้าที่รับค่าผลรวมที่คำนวณได้และคืบควบคู่กับค่าน้ำหนักในการกำหนดว่าโหนดนั้นควรทำงาน (activate) หรือไม่ทำงาน (deactivate) เพื่อส่งผลลัพธ์ไปยังโหนดถัดไปในโครงข่าย
ฟังก์ชันกระตุ้นที่ได้รับความนิยมในการใช้งานใน Deep Learning มีหลายแบบ ต่อไปนี้เป็นตัวอย่างของฟังก์ชันกระตุ้นที่ได้รับความนิยม:
- Sigmoid Activation (ฟังก์ชันซิกมอยด์): f(x) = 1 / (1 + e^(-x))
- ReLU (Rectified Linear Unit) Activation: f(x) = max(0, x)
- Leaky ReLU Activation: f(x) = max(αx, x) โดยที่ α เป็นค่าคงที่ที่มีค่าน้อยกว่า 1
- Parametric ReLU Activation: f(x) = max(αx, x) โดยที่ α เป็นพารามิเตอร์ที่ใช้ในกระบวนการเรียนรู้
- Swish Activation: f(x) = x * sigmoid(x)
- Softmax Activation: ใช้ในการจำแนกหมวดหมู่แบบหลายคลาส แปลงค่าผลรวมให้อยู่ในรูปแบบความน่าจะเป็น (probability distribution)
เหตุการณ์ที่ใช้ฟังก์ชันกระตุ้นเหตุใด ขึ้นอยู่กับความซับซ้อนและเป้าหมายในงานที่กำหนด ฟังก์ชันซิกมอยด์ถูกใช้ในอดีต แต่ ReLU เป็นที่นิยมมากขึ้นในปัจจุบันเนื่องจากมีประสิทธิภาพในการลดปัญหาของค่าเกรดิเอนต์และเร็กติฟาย อย่างไรก็ตาม การเลือกใช้ฟังก์ชันกระตุ้นแบบไหนเป็นข้อให้คิดในการออกแบบและฝึกฝนโมเดลใน Deep Learning อย่างถูกต้องและเหมาะสม
Notes
ฟังก์ชันกระตุ้นแบบซิกมอยด์ (sigmoid activation function) มักถูกใช้ในงานทำนายแบบแยกประเภทสองกลุ่ม (binary classification) โดยที่ภารกิจคือการทำนายระหว่างสองคลาส (เช่น “ใช่” หรือ “ไม่ใช่”, “สแปม” หรือ “ไม่ใช่สแปม”) ฟังก์ชันซิกมอยด์จะรับค่านำเข้าที่เป็นตัวเลขและแมปเปิลเป็นค่าระหว่าง 0 ถึง 1 ทำให้เหมาะสำหรับงานที่เป็นแบบแยกประเภทสองกลุ่ม เนื่องจากสามารถตีความได้เป็นค่านิยมความเป็นไปได้ (probability score) สำหรับคลาสหนึ่งหนึ่ง
ขณะที่ ฟังก์ชันกระตุ้นแบบซอฟต์แม็กซ์ (softmax activation function) จะถูกใช้สำหรับงานทำนายแบบหลายกลุ่ม (multiclass classification) โดยที่มีคลาสมากกว่าสองกลุ่มที่ต้องทำนาย ฟังก์ชันซอฟต์แม็กซ์จะรับเวกเตอร์ของค่านำเข้าที่เป็นตัวเลขและทำให้ค่านำเข้าทั้งหมดมีค่าเป็นระหว่าง 0 ถึง 1 โดยที่ผลรวมของความน่าจะเป็นในทุกๆ คลาสเท่ากับ 1 เหมาะสำหรับงานที่เป็นแบบหลายกลุ่มที่ต้องกำหนดค่านิยมความน่าจะเป็นให้กับแต่ละกลุ่ม
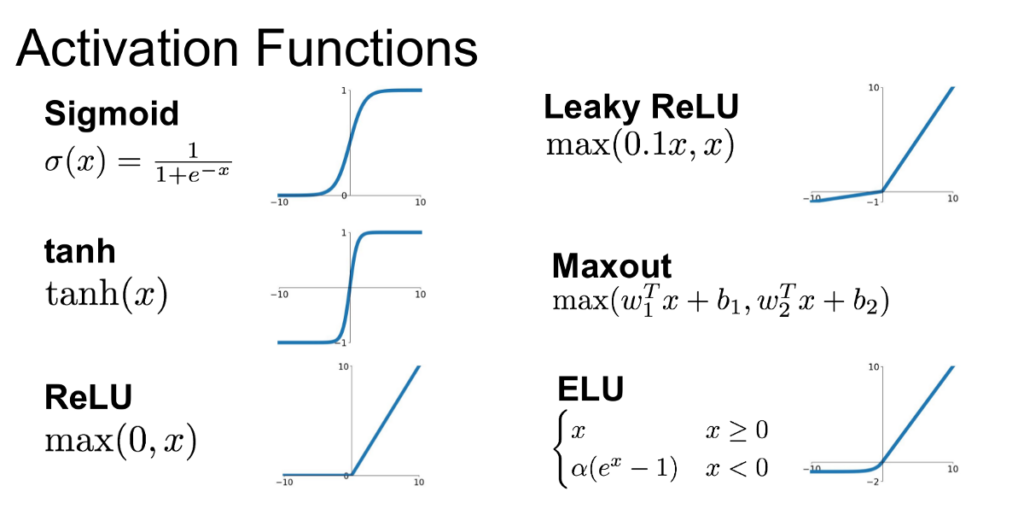
ภาพจาก https://medium.com/@shrutijadon/survey-on-activation-functions-for-deep-learning-9689331ba092https://medium.com/@shrutijadon/survey-on-activation-functions-for-deep-learning-9689331ba092
นี่คือค่าของฟังก์ชันกระตุ้นแบบซิกมอยด์ (sigmoid), ReLU, และฟังก์ชันหุ้มหงาย (tanh) รวมถึงฟังก์ชันกระตุ้นแบบซอฟต์แม็กซ์ (softmax) สำหรับค่านำเข้าที่อยู่ระหว่าง -∞ ถึง +∞:
- ฟังก์ชันกระตุ้นแบบซิกมอยด์:
- สูตร: f(x) = 1 / (1 + exp(-x))
- ช่วงค่า: (0, 1)
- f(-∞) ประมาณ 0
- f(0) = 0.5
- f(+∞) ประมาณ 1
- ฟังก์ชันหุ้มหงาย (ReLU – Rectified Linear Unit):
- สูตร: f(x) = max(0, x)
- ช่วงค่า: [0, +∞)
- f(-∞) = 0
- f(0) = 0
- f(+∞) = +∞
- ฟังก์ชันหุ้มหงายแบบแทน (tanh – Hyperbolic Tangent):
- สูตร: f(x) = (exp(x) – exp(-x)) / (exp(x) + exp(-x))
- ช่วงค่า: (-1, 1)
- f(-∞) ประมาณ -1
- f(0) = 0
- f(+∞) ประมาณ 1
- ฟังก์ชันกระตุ้นแบบซอฟต์แม็กซ์ (สำหรับการจำแนกหลายคลาส):
- สูตร: f(x_i) = exp(x_i) / (∑(exp(x_j)) สำหรับ j ในคลาสทั้งหมด)
- ช่วงค่า: (0, 1) สำหรับความน่าจะเป็นของแต่ละคลาส
- ฟังก์ชันซอฟต์แม็กซ์ถูกใช้ในงานทำนายแบบหลายกลุ่มเพื่อแปลงเวกเตอร์ของค่าเกรดต์มาเป็นการแจกแจงความน่าจะเป็นของคลาสทั้งหมด ผลรวมของความน่าจะเป็นทั้งหมดจะเท่ากับ 1