Convolutional Neural Network (CNN) เป็นประเภทของโครงข่ายประสาทเทียม (Neural Network) ที่ใช้ในการประมวลผลข้อมูลที่มีลักษณะเป็นภาพและข้อมูลที่มีลักษณะเชิงพื้นที่ โครงสร้างของ CNN ถูกออกแบบให้เหมาะสำหรับการตรวจสอบและสกัดลักษณะที่เกี่ยวข้องในข้อมูลที่มีมิติสูงเช่นภาพ วิดีโอ และเสียง
โครงสร้างของ CNN ประกอบด้วยเลเยอร์พื้นฐานดังนี้:
- Convolutional Layer (เลเยอร์การคอนโวลูชัน): ใช้ในการสกัดลักษณะ (feature extraction) จากข้อมูลนำเข้าโดยใช้การทำซ้ำของตัวกรอง (filter) เพื่อหาคุณลักษณะที่เกี่ยวข้อง
- Activation Function Layer (เลเยอร์ฟังก์ชันการกระตุ้น): ใช้ในการเปลี่ยนค่าผลลัพธ์ของเลเยอร์คอนโวลูชันให้เป็นค่าไม่เชิงเส้น โดยที่ฟังก์ชันที่ใช้มักเป็น ReLU (Rectified Linear Unit) หรือ Leaky ReLU
- Pooling Layer (เลเยอร์การกระจาย): ใช้ในการลดขนาดข้อมูลที่ผ่านเลเยอร์คอนโวลูชัน โดยสกัดค่าที่สำคัญเพื่อลดขนาดของภาพและลดซับซ้อนในการคำนวณ
- Fully-Connected Layer (เลเยอร์การเชื่อมต่อแบบเต็ม): เป็นเลเยอร์ที่คล้ายกับโครงข่ายประสาทเทียมแบบแบบ (Feedforward Neural Network) ซึ่งใช้ในการรวมลักษณะที่สกัดได้จากเลเยอร์ก่อนหน้าและให้ผลลัพธ์ที่สอดคล้องกับเป้าหมายของการจำแนกหรือการทำนาย
โครงสร้างของ CNN ช่วยให้โมเดลมีความสามารถในการจำแนกหรือสกัดลักษณะในข้อมูลที่มีมิติสูง เช่น ภาพที่มีความเกี่ยวข้องกับการจำแนกออบเจ็กต์ และมีความเหมาะสำหรับงานที่ต้องการความรวดเร็วและความเท่าเทียมในการคำนวณ
Kernal (เคอร์นัล) เป็นตัวกรองหรือมัสก์ที่ใช้ในการสกัดลักษณะ (feature extraction) จากข้อมูลนำเข้าในโครงข่ายประสาทเทียมแบบคอนโวลูชัน (Convolutional Neural Networks) โครงข่ายประสาทเทียมทำการคำนวณค่าผลลัพธ์โดยการนำตัวกรองหรือเคอร์นัลมาถ่วงค่าข้อมูลนำเข้าเพื่อให้ได้ลักษณะที่สำคัญและเกี่ยวข้องกับงานที่ต้องการทำ
เคอร์นัลมีความสำคัญในการทำคอนโวลูชันเนื่องจากมีความเกี่ยวข้องกับการสกัดคุณลักษณะที่ต้องการให้กับโมเดล การคำนวณของเคอร์นัลใช้กระบวนการคอนโวลูชันเพื่อหาคุณลักษณะที่สำคัญที่อยู่ในพื้นที่ของข้อมูลที่นำเข้า ซึ่งจะช่วยให้โมเดลมีความสามารถในการจำแนกหรือสกัดลักษณะในข้อมูลที่มีมิติสูง เช่น ภาพที่มีความเกี่ยวข้องกับการจำแนกออบเจ็กต์ และการประมวลผลเสียง โครงสร้างของเคอร์นัลมักเป็นเมตริกซ์หรือเวกเตอร์ที่มีขนาดเล็กเพื่อนำมาคำนวณกับข้อมูลนำเข้า และมักถูกปรับแต่งให้เหมาะสำหรับงานที่ต้องการทำให้เห็นความเกี่ยวข้อง การประกอบเคอร์นัลกับโครงข่ายประสาทเทียมช่วยเสริมสร้างความแม่นยำในการทำนายและจำแนกข้อมูลที่ซับซ้อนและมีลักษณะเป็นภาพ
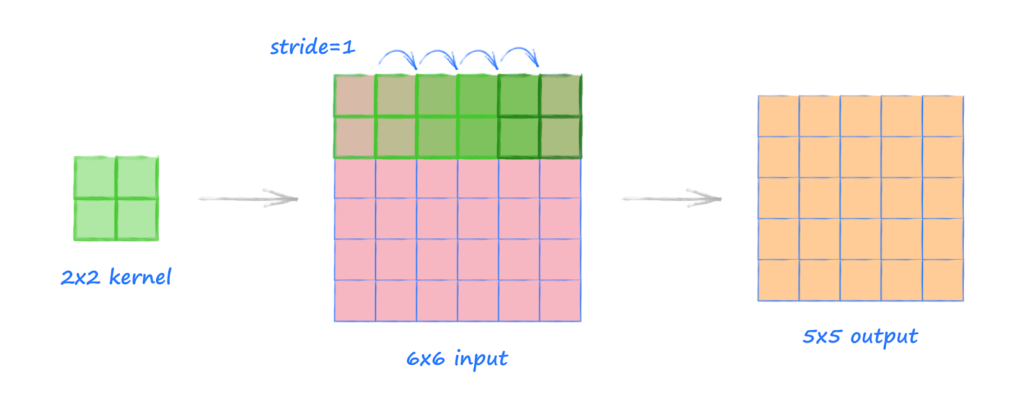
ภาพจาก http://makeyourownneuralnetwork.blogspot.com/2020/02/calculating-output-size-of-convolutions.html
https://deepai.org/machine-learning-glossary-and-terms/stride
ในบริบทของโครงข่ายประสาทเทียมแบบคอนโวลูชัน (Convolutional Neural Networks หรือ CNNs) คำว่า “kernel” และ “filter” มักถูกใช้แลกเปลี่ยนกัน แต่จริงๆ แล้วมีความแตกต่างเล็กน้อย
คำว่า “kernel” หมายถึงเมตริกซ์หรือตารางขนาดเล็กที่ใช้ในการประมวลผลข้อมูลนำเข้าในกระบวนการคอนโวลูชัน นั่นคือตัวกรองที่เป็นพารามิเตอร์ที่สามารถเรียนรู้และใช้สกัดลักษณะจากข้อมูลนำเข้า ซึ่งแต่ละค่าในเมตริกซ์จะถูกเรียนรู้ผ่านกระบวนการฝึกฝน (training) เพื่อให้สามารถสกัดคุณลักษณะที่สำคัญจากข้อมูลได้
อย่างไรก็ตาม คำว่า “filter” หมายถึงกระบวนการในการนำเคอร์นัลมาประมวลผลข้อมูลนำเข้า กระบวนการนี้เกี่ยวข้องกับการเลื่อนเคอร์นัลไปบนข้อมูลนำเข้าและคำนวณผลลัพธ์จากการคูณแบบเวกเตอร์ระหว่างเคอร์นัลและส่วนที่เกี่ยวข้องในข้อมูลที่นำเข้า ผลลัพธ์ของการคูณแบบเวกเตอร์นี้คือเอาท์พุตของการทำซ้ำของเคอร์นัลที่สำคัญที่ตัวกรองไปตามข้อมูลนำเข้า ซึ่งเป็นการสกัดคุณลักษณะ
นอกจากนี้ Stride (สไตรด์) เป็นองค์ประกอบหนึ่งของโครงข่ายประสาทเทียมแบบคอนโวลูชัน (Convolutional Neural Networks) หรือโครงข่ายประสาทเทียมที่ถูกปรับแต่งให้เหมาะสำหรับการบีบอัดข้อมูลภาพและวิดีโอ สไตรด์เป็นพารามิเตอร์ของตัวกรอง (filter) ในโครงข่ายประสาทเทียมที่แก้ไขจำนวนการเคลื่อนไหวของตัวกรองบนภาพหรือวิดีโอ
ตัวอย่างเช่น หากสไตรด์ในโครงข่ายประสาทเทียมถูกกำหนดให้เป็น 1 ตัวกรองจะเคลื่อนที่ไปหนึ่งพิกเซลหรือหน่วยในคราวเดียวกัน ขนาดของตัวกรองจะมีผลต่อปริมาณของข้อมูลที่ถูกเข้ารหัส ดังนั้นสไตรด์มักถูกกำหนดให้เป็นจำนวนเต็มเพื่อให้เหมาะสมกับการทำงาน และสิ่งสำคัญคือจะไม่กำหนดให้เป็นเศษหรือทศนิยม
สไตรด์ช่วยให้โครงข่ายประสาทเทียมมีความสามารถในการปรับแต่งการเคลื่อนไหวบนภาพหรือวิดีโอ มันเป็นสิ่งสำคัญในงานที่ต้องการความเร็วและความทันสมัยในการประมวลผลข้อมูล ทำให้สามารถนำไปใช้ในงานที่มีความซับซ้อนของข้อมูลที่มีมิติสูงเช่นการจำแนกวัตถุในภาพหรือการทำนายคุณลักษณะในวิดีโอได้อย่างมีประสิทธิภาพ
Padding (การเพิ่มพื้นที่ว่าง) เป็นเทคนิคหนึ่งที่ใช้ในโครงข่ายประสาทเทียมแบบคอนโวลูชัน (Convolutional Neural Networks หรือ CNNs) เพื่อปรับขนาดของภาพหรือข้อมูลนำเข้าให้เหมาะสมกับการคำนวณของตัวกรอง (filter) หรือเคอร์นัลที่ใช้ในกระบวนการคอนโวลูชัน
ในกระบวนการคอนโวลูชัน ขนาดของเอาท์พุต (output) จะมีขนาดเล็กกว่าขนาดของข้อมูลนำเข้า เนื่องจากการคำนวณแบบคอนโวลูชันจะทำให้ขนาดลดลง โดยพื้นที่ของเคอร์นัลที่สัมผัสกับข้อมูลนำเข้าจะเกิดขึ้นเพียงบริเตนหนึ่งของหน่วยหนึ่งในข้อมูลนำเข้า ซึ่งส่งผลให้ข้อมูลตอนของเอาท์พุตลดลง
เพื่อให้ข้อมูลเอาท์พุตมีขนาดเท่ากับข้อมูลนำเข้าหรือให้เหมาะสมกับการคำนวณต่อไป การเพิ่มพื้นที่ว่าง (padding) จะทำการเพิ่มพื้นที่เปล่าๆ รอบข้อมูลนำเข้าโดยเพิ่มค่าศูนย์หรือค่าที่กำหนดล่วงหน้าให้กับพื้นที่เพิ่มเติม ซึ่งทำให้ข้อมูลตอนของเอาท์พุตไม่ลดลง การเพิ่มพื้นที่ว่างนี้สามารถทำได้ในทั้งสองด้านของข้อมูลนำเข้าหรือในด้านที่สองข้าง
การใช้ padding ในโครงข่ายประสาทเทียมช่วยให้สามารถคำนวณหาคุณลักษณะที่เกี่ยวข้องในข้อมูลนำเข้าได้มากขึ้น และป้องกันการลดขนาดของข้อมูลเอาท์พุตที่อาจทำให้สูญเสียข้อมูลหรือสิ่งที่สำคัญได้ การใช้ padding นี้มีผลกระทบต่อการเพิ่มความซับซ้อนของโครงข่าย แต่ในบางกรณีการใช้ padding จำเป็นเพื่อให้ข้อมูลนำเข้าและเอาท์พุตมีขนาดเท่ากันหรือเหมาะสมกับงานที่ต้องการทำ
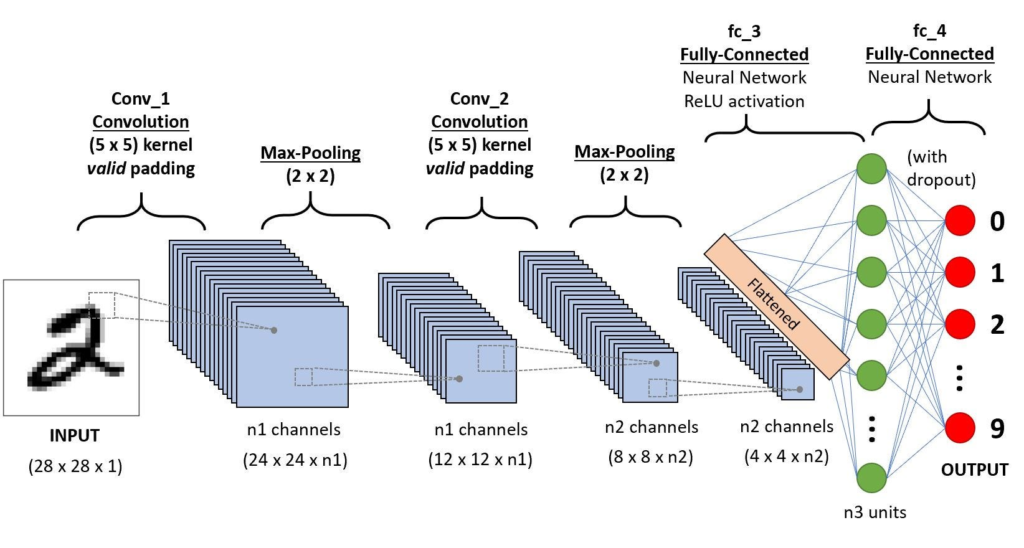
ภาพจาก https://saturncloud.io/blog/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way/