#Gradient Descent #learning rate
การปรับแต่ง (Optimization) เป็นขั้นตอนที่สำคัญในกระบวนการเรียนรู้ของโครงข่ายประสาทเทียม (Neural Networks) เพื่อให้โมเดลมีความแม่นยำและสามารถให้ผลลัพธ์ที่ดีที่สุดในการทำนายหรือตัดสินใจ เพื่อปรับค่าน้ำหนักของโครงข่ายประสาทเทียมให้เหมาะสมในการแก้ไขงานที่กำหนด มีอัลกอริทึมหลายรูปแบบที่สามารถใช้ในกระบวนการปรับแต่ง ดังนี้:
- Gradient Descent (SGD – Stochastic Gradient Descent): เป็นอัลกอริทึมที่ใช้คำนวณค่าความคลาดเคลื่อนและปรับค่าน้ำหนักโดยใช้การคำนวณเบี่ยงเบนมาตรฐาน (gradient) ของฟังก์ชันสูญเสีย (loss function) และใช้ค่า learning rate เพื่อกำหนดการเคลื่อนไหวในการปรับค่าน้ำหนัก
- Adam (Adaptive Moment Estimation): เป็นการปรับแต่งอัลกอริทึมที่เป็นความผสมระหว่าง Momentum และ RMSprop ทำให้การปรับค่าน้ำหนักเป็นไปอย่างมีประสิทธิภาพและความแม่นยำ
- RMSprop (Root Mean Square Propagation): เป็นอัลกอริทึมที่ใช้ในการปรับแต่งค่าน้ำหนัก โดยคิดคำนวณค่าเบียงเบนมาตรฐานของ gradient และใช้ค่าเสียตัดส่วน (learning rate) เพื่อปรับค่าน้ำหนัก
- AdaGrad (Adaptive Gradient Algorithm): เป็นการปรับแต่งอัลกอริทึมที่มีความสามารถในการปรับค่าน้ำหนักของแต่ละตัวแปรเพื่อให้แน่ใจว่าค่าเสียตัดส่วน (learning rate) ในแต่ละตัวแปรน้อยลงเมื่อ gradient มีค่ามาก และมากขึ้นเมื่อ gradient มีค่าน้อย
- AdaDelta: เป็นการปรับแต่งอัลกอริทึมที่เป็นการแก้ปัญหาของ AdaGrad ซึ่งอาจมีปัญหาในความเร็วในการเรียนรู้
อัลกอริทึมต่างๆ นี้มีลักษณะและการทำงานที่ต่างกัน และสามารถนำมาประยุกต์ใช้กับโครงข่ายประสาทเทียมต่างๆ ตามความเหมาะสมของงานและการแก้ไขปัญหาที่กำหนด
เพิ่มเติม
Loss Function (ฟังก์ชันสูญเสีย) เป็นฟังก์ชันที่ใช้ในการวัดความคลาดเคลื่อนระหว่างค่าผลลัพธ์ที่โมเดลทำนายและค่าเป้าหมาย (ground truth) ในกระบวนการเรียนรู้ของโมเดล ความคลาดเคลื่อนคือค่าความแตกต่างระหว่างผลลัพธ์ที่โมเดลทำนายกับผลลัพธ์ที่ถูกต้องจริงๆ โดยฟังก์ชันสูญเสียจะเป็นค่าที่ต้องการให้มีค่าน้อยที่สุด เพื่อให้โมเดลมีความแม่นยำในการทำนาย
Gradient Descent (กระบวนการเคลื่อนที่แบบเกรเดียน): เป็นอัลกอริทึมที่ใช้ในการปรับค่าน้ำหนักของโครงข่ายประสาทเทียมเพื่อลดค่าความคลาดเคลื่อน ความคลาดเคลื่อนของโมเดลสามารถคำนวณได้จากการนำเสนอข้อมูลทดสอบและค่าเป้าหมาย เมื่อคำนวณความคลาดเคลื่อนเสร็จสิ้น การ Gradient Descent จะใช้ค่าน้ำหนักเดิมและค่าคลาดเคลื่อนในการปรับค่าน้ำหนักในทิศทางที่ลดค่าคลาดเคลื่อน โดยใช้ learning rate เพื่อกำหนดขนาดของการเคลื่อนที่
Learning Rate (อัตราการเรียนรู้): เป็นพารามิเตอร์ที่ใช้ในการกำหนดขนาดของการเคลื่อนที่ในกระบวนการ Gradient Descent ซึ่งกำหนดความเร็วในการปรับค่าน้ำหนักของโครงข่าย ถ้า learning rate มีค่าสูง การเรียนรู้จะเกิดขึ้นเร็วขึ้น แต่อาจทำให้การเรียนรู้ไม่เสถียร หาก learning rate มีค่าน้อย การเรียนรู้จะเกิดขึ้นช้าขึ้น แต่จะมีความเสถียรในการเรียนรู้มากขึ้น
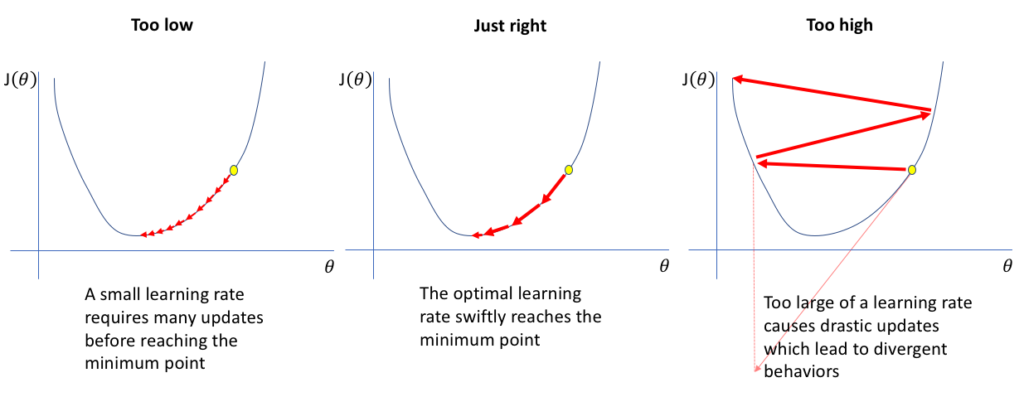
ภาพจาก https://www.jeremyjordan.me/nn-learning-rate/
Learning Rate (อัตราการเรียนรู้) ใน Deep Learning คือพารามิเตอร์ที่กำหนดความเร็วในกระบวนการปรับค่าน้ำหนักของโครงข่ายประสาทเทียม หรืออัลกอริทึมการเคลื่อนที่แบบเกรเดียน (Gradient Descent) เพื่อลดค่าความคลาดเคลื่อน (loss) ของโมเดลในแต่ละรอบของการฝึกฝน (epoch) ซึ่งมีผลต่อการปรับค่าน้ำหนักและความเร็วในการเรียนรู้ของโมเดล ความเร็วในการเรียนรู้ของโมเดลขึ้นอยู่กับค่า learning rate ที่เลือกใช้ มีความสำคัญในการปรับค่าน้ำหนักในทิศทางที่ช่วยลดค่าความคลาดเคลื่อนของโมเดลไปใกล้ค่าต่ำสุด หากเลือกค่า learning rate ที่เหมาะสม โมเดลสามารถเรียนรู้และทำนายได้ดี แต่หากค่า learning rate มีค่าเกินมากจะทำให้การเรียนรู้เร็วจนทำให้โมเดลเกิดปัญหาในการเรียนรู้เกินไป (เรียกว่า overfitting) ส่วนค่า learning rate ที่เกินน้อยกว่ามาตรฐานอาจทำให้โมเดลเรียนรู้ช้าเกินไป (เรียกว่า underfitting) ในกระบวนการการปรับแต่งค่าน้ำหนักด้วย Gradient Descent อย่างมีระดับ การเคลื่อนที่ของโมเดลเป็นลักษณะการแกว่งไปมาเพื่อลดค่าความคลาดเคลื่อน หากในระหว่างการเรียนรู้มีความเสี่ยงที่จะติดอยู่ที่จุดต่ำสุดที่ไม่ใช่จุดต่ำสุดที่ถูกต้อง (global minimum) เรียกว่าติดตัวแย่ (local minimum) หรือจุดต่ำสุดเท่านั้น (saddle points) ซึ่งอาจส่งผลให้โมเดลไม่สามารถเรียนรู้ได้ถูกต้อง ความเร็วในการเรียนรู้ของโมเดลอาจช่วยในกระบวนการลดความเสี่ยงในการติดตัวแย่ แต่ยังคงขึ้นอยู่กับการเลือกค่า hyperparameters ที่เหมาะสมและความซับซ้อนของโมเดลที่กำหนด
อยากทำความเข้าใจง่ายกว่านี้ในการเดิน step ของ gradient descent สามารถดูได้ทางนี้