
LangChain เป็นเฟรมเวิร์กโอเพนซอร์สสำหรับสร้างแอปพลิเคชันโดยใช้แบบจำลองภาษาขนาดใหญ่ (LLMs) ได้รับการออกแบบมาเพื่อให้ง่ายต่อการสร้างแอปพลิเคชันที่ซับซ้อนที่โต้ตอบกับ LLMs ในลักษณะที่เป็นธรรมชาติ LangChain มีคุณสมบัติหลายอย่างที่ทำให้ง่ายต่อการสร้างแอปพลิเคชันที่ใช้ LLM ได้แก่:
- API ง่ายๆ สำหรับการโต้ตอบกับ LLMs
- ระบบท่อในตัวสำหรับเชื่อมต่อ LLM หลายตัวเข้าด้วยกัน
- ระบบหน่วยความจำสำหรับจัดเก็บและดึงข้อมูลจาก LLMs
- ตัวดีบักสำหรับดีบักแอปพลิเคชันที่ใช้ LLM
LangChain ยังคงอยู่ระหว่างการพัฒนา แต่ได้ถูกใช้ในการสร้างแอปพลิเคชั่นที่น่าประทับใจจำนวนหนึ่งแล้ว ได้แก่:
- แชทบอตที่สามารถสนทนากับมนุษย์ได้
- ตัวสร้างรหัสที่สามารถสร้างรหัสจากคำอธิบายภาษาธรรมชาติ
- เครื่องมือสรุปที่สามารถสรุปเอกสารในลักษณะที่เป็นธรรมชาติ
LangChain เป็นเครื่องมือที่ทรงพลังที่สามารถใช้ในการสร้างแอปพลิเคชั่นที่หลากหลาย หากคุณสนใจที่จะสร้างแอปพลิเคชั่นที่ใช้ LLMs LangChain เป็นจุดเริ่มต้นที่ดี
ต่อไปนี้คือประโยชน์บางประการของการใช้ LangChain:
- ใช้งานง่าย API นั้นง่ายและตรงไปตรงมาและเอกสารนั้นชัดเจนและกระชับ
- มีประสิทธิภาพ LangChain มีคุณลักษณะหลายอย่างที่ทำให้ง่ายต่อการสร้างแอปพลิเคชันที่ซับซ้อน
- ขยายได้ LangChain เป็นโอเพนซอร์สดังนั้นคุณสามารถขยายเพื่อตอบสนองความต้องการเฉพาะของคุณ
วิธีการทำงานของ LangChain
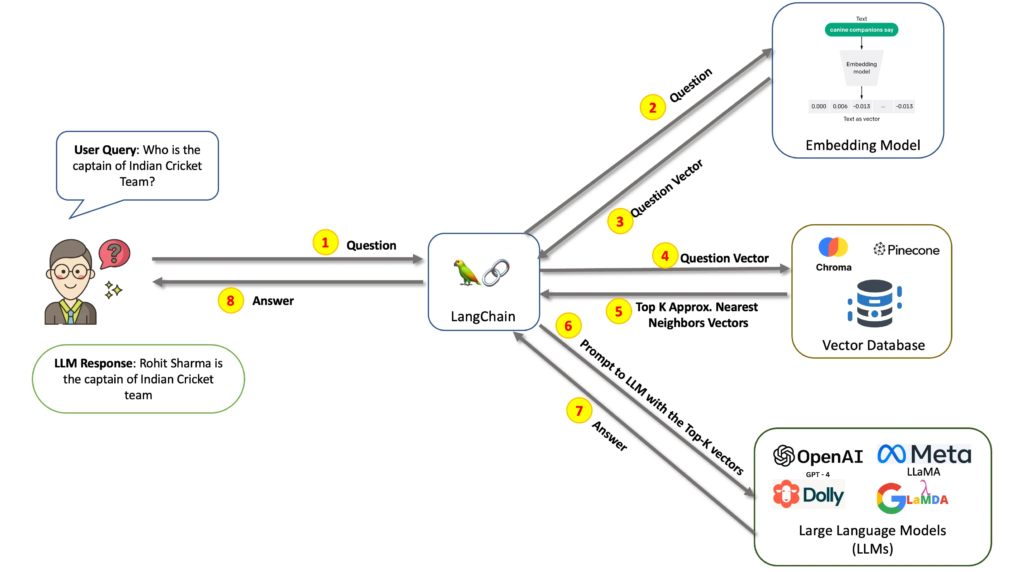
ภาพจาก https://ashukumar27.medium.com/the-agents-of-ai-1402548e9b8c
user จะตั้งคำถามขึ้นหลังจากนั้นคำถามจะถูกส่งต่อไปยัง embedding model ) มีหน้าที่ในกระบวนการแปลงข้อมูลที่เป็นคำหรือเอนทิตีในภาษาธรรมชาติเป็นเวกเตอร์ของตัวเลขในพื้นที่เชิงเส้น (vector space) ทำให้ข้อมูลที่เป็นภาษาสามารถนำมาใช้ในการฝึกฝนและประมวลผลโดยโมเดลที่มีลักษณะเป็นตัวเลขได้ง่ายและมีประสิทธิภาพมากขึ้น จากนั้นคำถามจะถูกแปลงมาเป็น question vector ผ่าน LangChain ส่งต่อไปยัง vector database ซึ่งทำหน้าที่เก็บข้อมูลเวกเตอร์ที่เกี่ยวข้องกับข้อความหรือเอนทิตีในภาษาธรรมชาติ ซึ่งเป็นข้อมูลที่ถูกแปลงจากข้อความให้เป็นเลขที่สามารถนำมาใช้ในการฝึกฝนและประมวลผลโดยโมเดลที่มีลักษณะเป็นตัวเลขได้ง่ายและมีประสิทธิภาพ
Vector database มีความสำคัญในการนำข้อมูลภาษามาใช้ในการประมวลผลด้านต่างๆ เช่น การจำแนกประเภทของข้อความ (text classification) หาความคล้ายคลึงกันระหว่างข้อความ (text similarity) หรือการแปลภาษา (machine translation) โดยการใช้เวกเตอร์ที่ถูกเก็บในฐานข้อมูล นอกจากนี้ยังช่วยให้การค้นหาข้อมูลที่เกี่ยวข้องกับข้อความมีประสิทธิภาพและเร็วขึ้น หลังจากนั้น K-nearest neighbor (K-NN) vector ทำหน้าที่ในการจำแนกและหาความคล้ายคลึงกันของข้อมูลในเวกเตอร์ที่อยู่ใกล้กันในพื้นที่เชิงเส้น (vector space) โดยการใช้ค่าระยะห่างหรือความคล้ายคลึงระหว่างข้อมูลที่มีอยู่ในฐานข้อมูลกับข้อมูลที่ต้องการจำแนกหรือหาความคล้ายคลึงกัน และส่งกลับไปยัง LangChain ก่อนที่ LangChain จะส่ง Prompt ไปยัง โมเดลภาษาขนาดใหญ่ ประมวลผลออกมาเป็นคำตอบของคำถามนั่นเอง